목표
GCP의 Compute Engine과 Cloud SQL을 이용해서 SpringBoot 프로젝트 서버 구축하기
준비
1. 빌드된 SpringBoot 프로젝트 (*.jar 파일)
방법
1. Google Cloud Platform의 새로운 계정을 만들어서 프리티어 이용하기
2. 사용할 Project 선택하기
링크 => https://console.cloud.google.com/

3. Cloud SQL로 데이터베이스 만들기
3-1. 메뉴에서 SQL 메뉴로 이동

3-2. Cloud SQL 인스턴스 만들기





CREATE INSTANCE 버튼을 누르면 완료
(이후 인스턴스 생성되는 시간이 꽤 걸리므로 4. Compute Engine에서 VM 인스턴스 만들기를 먼저해도 됨)
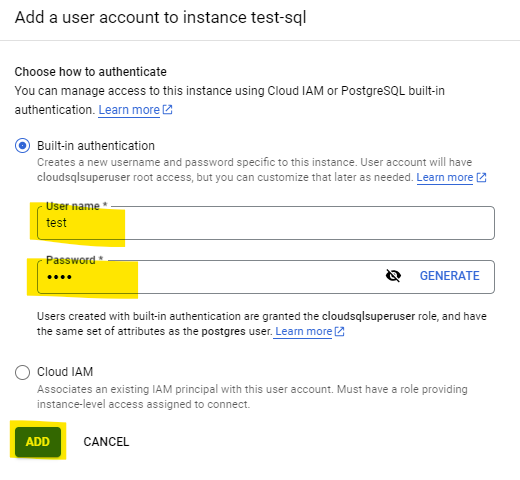
3-3. 유저 만들기
SpringBoot 프로젝트에서 데이터베이스 연결할 username과 password 생성

3-4. 데이터베이스 만들기


3-5. 외부에서 데이터베이스 접속가능하게 하기



모든 네트워크에서 접속가능하게 하려면 0.0.0.0/0을 입력한다
특정 네트워크만 허용해도 된다
Save 누르면 완료
4. Compute Engine에서 VM 인스턴스 만들기
4-1. 인스턴스 생성하기






CREATE 버튼을 누르면 완료
4-2. VM 인스턴스의 고정 IP 주소 만들기
현재는 외부/내부 임시 IP로 구성되어 있으므로 외부 고정 IP를 만든다
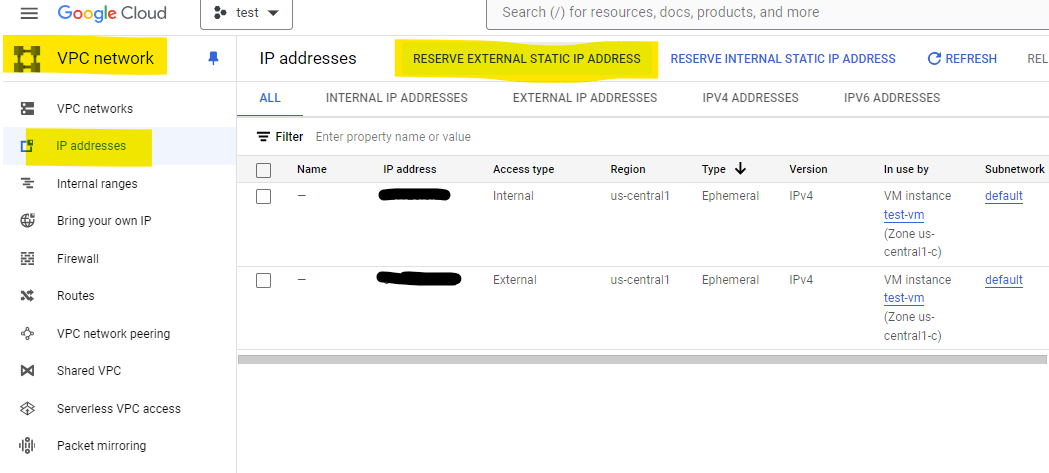

Reserve 버튼을 누르면 완료
4-3. 포트(Port) 열어주기
SpringBoot의 기본 포트인 8080을 열어준다



Create 버튼 누르면 완료
5. SSH Key 발급하고 VM Instance에 등록하기
1. SSH KEY 발급하는 방법 => https://cloud.google.com/compute/docs/connect/create-ssh-keys?hl=ko#linux-and-macos
2. SSH Key 중에 .pub으로 끝나는 파일의 내용을 복사한다
3. 다음으로


Save 누르면 완료
6. VSCode에서 SSH로 VM 인스턴스에 연결하기
7. VM 인스턴스에서 SpringBoot 실행하기

1. api 폴더(아무 이름의 폴더)를 만듭니다.
2. SpringBoot를 빌드한 파일과 application.properties 또는 application.yml을 옮깁니다.
(이 환경 설정 파일에서 database 관련 설정을 Cloud SQL에서 만들었던 정보들로 수정)
spring.datasource.url=jdbc:postgresql://[Cloud Sql Instance의 Public IP]/[만든 데이터베이스 이름]?useSSL=false&characterEncoding=UTF-8
spring.datasource.username=[만든 유저 이름]
spring.datasource.password=[만든 유저 비밀번호]3. 터미널에서 api 폴더로 이동한 합니다.
4. SpringBoot를 백그라운드에서 중단 없이 실행하는 명령어를 입력합니다.
nohup java -jar [빌드파일이름].jar &
'개발 > GCP' 카테고리의 다른 글
| [springboot + firebase admin storage + app engine] config 초기화 오류 해결 (0) | 2024.01.13 |
|---|---|
| [GCP] Compute Engine, App Engine, Kubernetes Engine의 차이점 (0) | 2023.09.13 |
| [GCP] App Engine에서 Node.js + Postgres 앱 빌드하기 (0) | 2023.09.08 |
| 도커 (0) | 2023.08.23 |




